前方高能,目测是本站最长文章 qwq
快 NOIP 了,于是自己就复习一下所学的知识,自己回想起来认真学 OI 也就不到一年 (论没学长带学 OI 的后果)
学的知识也不是很多,但是我还不想现在退役啊 qwq,好不容易自己终于能和 dalao 并肩说话了 qwq
这里没有给出关于 DP,搜索和数据结构这类的模板 (太长了,不会写 QvQ)
这里发一个自己学的算法模板总结,其中里面有一些提醒 (主要是自己 MDZZ 的时候的错误)
欢迎 dalao 来查错 qwq
字符串
KMP && hash 给定一个字符串 $A$ 和一个字符串 $B$,求 $B$ 在 $A$ 中的出现次数。
//下标从 1 开始,如果从 0 开始 就 i-1
const int maxn = 1e6+7;
char s[maxn],kmp[maxn];
int nexts[maxn],n,lens,len;
int make_k(){
len=strlen(kmp+1);
int j=0,ans=0;
fors(i,2,len){//从第二位开始匹配,保持 j+1
while(j && kmp[i]!=kmp[j+1]) j=nexts[j];
nexts[i] = kmp[i] == kmp[j+1] ? ++j : 0;
}
j=0;
lens=strlen(s+1);
fors(i,1,lens){
while(j && s[i] != kmp[j+1]) j=nexts[j];
j += s[i] == kmp[j+1] ;
if(j == len) ++ans;
}
return ans;
}
int main(int argc, char const *argv[])
{
scanf("%s%s",s+1,kmp+1);
writen(make_k());
return 0;
}
// hash
const ull hashs=23333333;
ull pows=1,sum[maxn];
int main(int argc, char const *argv[])
{
scanf("%s%s",s+1,kmp+1);
lens=strlen(s+1),lenb=strlen(kmp+1);
fors(i,1,lenb) pows=pows*hashs;
fors(i,1,lens){
sum[i]=sum[i-1] * hashs + (ull) (s[i] - 'a' + 1);
}
ull now = 0;
for(int i=1;i <= lenb; ++i){
now = now * hashs + (ull) (kmp[i] - 'a' + 1);
}
int ans=0;
for(int i=0; i + lenb <= lens;++i){
if(now == sum[i + lenb] - sum[i] * pows)
++ans;
}
writen(ans);
return 0;
}
Manacher 求 S 中最长回文串的长度.
Manacher 利用回文对称的性质,来简化求以一个字符为对称轴的最大的回文长度
int n,m,hw[maxn];
char a[maxn],s[maxn<<1];
void manacher(){
int maxr = 0 , mid = 0 ;//maxr,表示已经触及到的最右边的字符
fors(i,0,n){
if(i < maxr)//i 关于 mid 的对称点为 j - > mid*2-i,
hw[i] = min(hw[mid * 2 - i] , hw[mid] + mid - i);
else //当 i 在 maxr 右边时,我们无法得知关于 hw[i] 的信息,只好从 1 开始遍历,然后更新 maxr 和 mid
hw[i] = 1;
while(s[i + hw[i]] == s[i - hw[i]])//扩展回文长度
++hw[i];
if(hw[i] + i > maxr){
maxr = hw[i] + i;
mid = i;
}
}
}
//回文串长度的奇偶性造成了对称轴的位置可能在某字符上,也可能在两个字符之间的空隙处,要对两种情况分别处理
void chage(){
s[0] = s[1] = '#';//加入'#'使得长度为偶数就解决了
fors(i,0,n){
s[i*2 + 2] = a[i];
s[i*2 + 3] = '#';
}
n = n + n + 2;
s[n] = 0;
}
int main()
{
scanf("%s",a);
n = strlen(a);
chage();
manacher();
int ans = 1;
fors(i,0,n){
ans = max(ans , hw[i]);
}
writen(ans-1);//回文要-1 qwq
return 0;
}
图论
并查集
int f[maxn],ans,n,m,tot,k[maxn];
const int mod=998244353;
int find(int x){
return f[x] == x ? x : (f[x] = find(f[x]));
}
int main(int argc, char const *argv[])
{
n=read(),m=read();
fors(i,1,n)
f[i]=i;
fors(i,1,m){
int op=read(),u=read(),v=read();
if(!op){
int a=find(u),b=find(v);
if(a!=b) {
f[b]=a;
}
}
else{
ans=ans<<1|(find(u) == find(v));
ans%=mod;
}
}
writen(ans);
return 0;
}
最短路
首先简单的
// floyd 多源最短路 计算类似矩阵乘法
int edge[2505][2505];
void floyd(){
fors(k,1,n)
fors(i,1,n)
fors(j,1,n)
edge[i][j]=min(edge[i][j],edge[i][k]+edge[k][j]);
}
int main(int argc, char const *argv[])
{
n=read(),m=read(),s=read(),t=read();
mem(edge,63);
edge[p][p]=0;
fors(i,1,m){
int a=read(),b=read(),c=read();
edge[a][b]=edge[b][a]=min(edge[a][b],c);
}
floyd();
writen(edge[s][t]);
return 0;
}
//SPFA 加优化更慢!!!
struct node
{
int u,v,val;
}edge[maxn];
void add(int u,int v,int w){
edge[++tot].v=v,edge[tot].u=head[u],head[u]=tot,edge[tot].val=w;
}//链式前向星
void spfa(){
mem(dis,127);
vis[s]=1;
q.push(s);
dis[s]=0;
while(!q.empty()){
int u=q.front();
q.pop();
vis[u]=0;
for(int v,i=head[u];i;i=edge[i].u){
v=edge[i].v;
if(dis[v] > dis[u] + edge[i].val){
dis[v] = dis[u] + edge[i].val;
if(!vis[v]){
vis[v]=1;
q.push(v);
}
}
}
}
}
优秀的 Dijkstra 算法

然而我写不来 Fib 优化。。。点多的用 zkw,点少的 stl
// 暴力
void dijkstra(){
mem(dis,63);
int u=s;
dis[u]=0;
while(!vis[u]){
vis[u] = 1;
for(int v,i=head[u];i;i=edge[i].u){
v=edge[i].v;
if(!vis[v] && dis[v] > dis[u] + edge[i].val){
dis[v] = dis[u] + edge[i].val;
}
}
int mins=1<<30;
fors(i,1,n){
if(!vis[i] && mins > dis[i]){
mins = dis[i];
u = i;
}
}
}
}
// 堆优化
struct node{
int num,dis;
friend bool operator < (node a,node b){
if(a.dis==b.dis) return a.num>b.num;
return a.dis>b.dis;
}
};
inline void add(int u,int v,int w){
e[++tot]=(cp){head[u],v,w};
head[u]=tot;
}
priority_queue<node> q;
void Dijkstra(){
memset(dis,63,sizeof dis);
dis[s]=0;
q.push((node){s,0});
while(!q.empty()){
node u=q.top();q.pop();
if(u.dis!=dis[u.num])
continue;
for(int i=head[u.num];i;i=e[i].next){
int v=e[i].to;
if(dis[v]>u.dis+e[i].val)
dis[v]=u.dis+e[i].val,q.push((node){v,dis[v]});
}
}
}
//ZKW 线段树
int n,m,s,t,N,tree[maxn<<1],dis[maxn],vis[maxn],tot,head[maxn];
struct node
{
int u,v,val;
}edge[maxn<<1];
void build(){
for(N = 1 ; N < n;N <<= 1)
;
--N;
fors(i,1,n)
tree[i+N] = i;
for(int i=N; i ; --i)
tree[i] = dis[ tree[i<<1] ] < dis[ tree[i<<1|1] ] ? tree[i<<1] : tree[i<<1|1];
}
void update(int x){
for(int i=(x + N) >> 1 ; i ; i>>=1)
tree[i] = dis[ tree[i<<1] ] < dis[ tree[i<<1|1] ] ? tree[i<<1] : tree[i<<1|1];
}
void add(int u,int v,int w){
edge[++tot].v=v,edge[tot].u=head[u],head[u]=tot;edge[tot].val=w;
}
void Dijkstra(){
mem(dis,127);
dis[s]=0;//先赋值 再建树
build();
mem(vis,0);
fors(i,1,n){
int u=tree[1];//以最小的初始化
//tree[] 存的是 dis 最小节点的编号,出队最小节点
vis[u]=1;
tree[u + N] = 0;//默认 0 号节点 dis 为无穷大,相当于出队 x
update(u);
for(int i=head[u] ; i ; i=edge[i].u){
int &v=edge[i].v;
if(!vis[v] && dis[v] > dis[u] + edge[i].val){
dis[v] = dis[u] + edge[i].val;
update(v);//每次更新
}
}
}
}
最小生成树
//Kruskal
// 并查集+sort b 不需要连反向边之类的因为 主要是对边权排序
struct node
{
int u,v,val;
bool operator < (const node &ano) const {
return val < ano.val;
}
}edge[maxn];
int m,n;
int f[maxn];
int find(int x){
return f[x]==x ? x : (f[x] = find(f[x]));
}
int tot;
ll ans;
void kroual(){
fors(i,1,n)
f[i]=i;
sort(edge+1,edge+tot+1);
fors(i,1,m){
int a=find(edge[i].u),b=find(edge[i].v);
if(a!=b){
f[b]=a;
ans+=edge[i].val;
}
}
}
int main(int argc, char const *argv[])
{
n=read(),m=read();
fors(i,1,m){
int a=read(),b=read(),c=read();
edge[++tot]=(node){a,b,c};
}
kroual();
writen(ans);
return 0;
}
// Prim + priority //需要连反向边
struct node
{
int u,v,val;
}edge[maxn];
int n,m,head[maxn],tot,vis[maxn],dis[maxn];
ll ans;
void add(int u,int v,int val){
edge[++tot].v=v,edge[tot].u=head[u],head[u]=tot;edge[tot].val=val;
}
typedef pair<int,int> pii;
priority_queue<pii , vector<pii> , greater<pii> > q;
void prim(){
mem(dis,127);
dis[1] = 0;
int cnt=0;
q.push(make_pair(0,1));
while(!q.empty() && cnt < n){
int tmpd=q.top().first,u=q.top().second;
q.pop();
if(vis[u]) continue;
vis[u] = 1;
++cnt;
ans+=tmpd;
for(int v,i=head[u] ; i ;i=edge[i].u){
v=edge[i].v;
if(edge[i].val < dis[v]){
dis[v] = edge[i].val;// 对边的大小判断
q.push(make_pair(dis[v],v));
}
}
}
}
负环判定
在 SPFA 里跑最短路记录每个点出现的次数,一个位置入队次数不小于 n 次, 那它一定位于环上
莫名奇妙,被 luogu 的模板题卡常了,明明和别人算法一样 迷 qwq
int SPFA(){
mem(dis,127);
nodeq q;//这里手写队列 qwq
q.push(1);
dis[1] = 0;
while(!q.empty()){
int u = q.front();
q.pop();
if(cnt[u] >= n) return 1;//当这是出队的点 出现次数大于 N 为负环
vis[u] = 0;
for(int i = head[u] ; i ;i = edge[i].u){
int v = edge[i].v;
if(dis[v] > dis[u] + edge[i].val){
dis[v] = dis[u] + edge[i].val;
if(!vis[v]){
vis[v] = 1;
++cnt[v];//在 vis 满足条件的里面 ++ 再判断
if(cnt[v] >= n ) return 1;
q.push(v);
}
}
}
}
return 0;
}
LCA 最近公共祖先
听说树链剖分写 LCA 省时间 (当时没学树剖,惊呆.avi)
然后一学,哇,什么都写树剖 qwq(我写树剖比倍增快多了 qwq)
每次求 $LCA(x,y)$的时候就可以判断两点是否在同一链上
如果两点在同一条链上我们只要找到这两点中深度较小的点输出就行了
如果两点不在同一条链上
那就找到深度较大的点令它等于它所在的重链链端的父节点即为 $x=f[top[x]]$
直到两点到达同一条链上,输出两点中深度较小的点
struct node
{
int u,v;
}edge[maxn];
int head[maxn],tot;
void add(int u,int v){
edge[++tot].u = head[u];
edge[tot].v = v;
head[u] = tot;
}
int siz[maxn],son[maxn],fa[maxn],tops[maxn],depth[maxn];
int n,m;
void dfs1(int u,int f,int dep){
fa[u] = f;//dfs1 处理深度,父亲,Size,儿子
depth[u] = dep;
siz[u] = 1;//记得初始化为 1, 不然会超时
int maxson = -1;//标记重儿子
for(int i = head[u];i;i=edge[i].u){
int v = edge[i].v;
if(v == f) continue;
dfs1(v,u,dep+1);//先 dfs 完再处理儿子
siz[u] += siz[v;//加上 Siz
if(maxson < siz[v]) maxson = siz[v] , son[u] = v;
}
}
void dfs2(int u,int topf){//dfs2 处理祖先
tops[u] = topf;
if(!son[u]) return;
//没有儿子直接 return,不然就遍历其儿子
dfs2(son[u],topf);//祖先是 topf 不是 u qwq
for(int i = head[u];i;i=edge[i].u){
int v = edge[i].v;
if(v == son[u] || v == fa[u]) continue;
dfs2(v,v);//每一 v 都有一条顶端为自己的链
}
}
int main(int argc, char const *argv[])
{
n = read() , m = read();
int s = read();
fors(i,1,n-1){
int u = read() ,v = read();
add(u,v);
add(v,u);
}
dfs1(s,0,1);//一定要预处理 qwq
dfs2(s,s);
fors(i,1,m){
int x = read() ,y = read();
while(tops[x] != tops[y]){//先判断祖先是否相同
if(depth[tops[x]] < depth[tops[y]]) swap(x,y);//将 x 换到祖先深度大的点
x = fa[tops[x]];//从祖先的父亲开始跳
}
writen(depth[x] < depth[y] ? x : y);//输出深度小的
}
return 0;
}
二分图匹配
对于一个图 G=(V,E),若能将其点集分为两个互不相交的两个子集 X、Y,
使得 X∩Y=∅,且对于 G 的边集 V,若其所有边的顶点全部一侧属于 X,
一侧属于 Y,则称图 G 为一个二分图。
- 当且仅当无向图 G 的回路个数为偶数时,图 G 为一个二分图。
无回路的图也是二分图。 -
在二分图 G 中,任选一个点 V,使用 BFS 算出其他点相对于 V 的距离(边权为 1)对于每一条边 E,枚举它的两个端点,若其两个端点的值,一个为奇数,一个为偶数,则图 G 为一个二分图。
-
对于一个二分图 G 的子图 M, 若 M 的边集 E 的的任意两条边都不连接同一个顶点,则称 M 为 G 的一个匹配。
-
对于二分图 G 的一个子图 M,若 M 为其边数最多的子图,则称 M 为 G 的最大匹配。
给定一个二分图,结点个数分别为 n,m,边数为 e,求二分图最大匹配数
int dfs(int u){
for(int i = head[u] ; i ; i = edge[i].u){
int v = edge[i].v;
if(!vis[v]){//如果相邻顶点已经被染成同色了, 说明不是二分图
vis[v] = 1;//如果相邻顶点没有被染色, 染成 c, 看相邻顶点是否满足要求
if((!point[v]) || dfs(point[v])){
point[v] = u;
return 1;
}
}
}
return 0;
}
int main(){
n = read() , m = read() , e = read();
fors(i,1,e){
int x = read() , y = read();
if(x>n||y>m) continue;
add(x,y+n);
add(y+n,x);
}
fors(i,1,n){
mem(vis,0);
if(dfs(i)) ++ans;
}
writen(ans);
return 0;
}
k 短路
由于不会 k 短路的正解,只能靠着 A* 水水 qwq
先上一个 A* 求 k 短路 的过程
算法过程:
- 将图反向,用 Dijstra+heap 求出 t 到所有点的最短距离,目的是求所有点到点 t 的最短路,用 dis[i] 表示 i 到 t 的最短路,其实这就是 $A*$的启发函数,显然:$h(n)$(U,fu+w[v][u],gv+w[v][u])$。
-
终止条件。每个节点最多入队列 $K$次,当 $t$出队列 $K$次时,即找到解。
int n,m;
struct e{
int u,v,val;
}edge[maxn],edge_hx[maxn];//edge_hx 表示 求解的正向边 , edge[] 求 Dijkstra 的反向最短路
int head[maxn],tot,head_hx[maxn],toth;
void add(int u,int v,int val){
edge[++tot].v = v;//如果不是双向边,一定要反向啊 qwq
edge[tot].u = head[u];
head[u] = tot;
edge[tot].val = val;
edge_hx[++toth].v = v;//正向图跑 A*
edge_hx[toth].u = head_hx[u];
head_hx[u] = toth;
edge_hx[toth].val = val;
}
struct node{
int num,dis;
bool operator < (const node &ano) const{
return dis==ano.dis ? num > ano.num : dis > ano.dis;
}
};
priority_queue<node> q;
int dis[maxn];
void Dijkstra(int ed){
memset(dis,127,sizeof dis);
dis[ed]=0;
q.push((node){ed,0});
while(!q.empty()){
node u=q.top();q.pop();
if(u.dis != dis[u.num]) continue;
for(int i=head[u.num];i;i=edge[i].u){
int v=edge[i].v;
if(dis[v] > u.dis+edge[i].val)
dis[v]=u.dis+edge[i].val,q.push((node){v,dis[v]});
}
}
}
struct Node
{
int x,val;
bool operator< (const Node &a)const{
return val+dis[x] > a.val+dis[a.x];
}//用于计算优先队列 , 估价函数 由于优先队列默认从大到小,所以重载也要反着来
};
priority_queue<Node>Q;//用于 A*
int cnt[maxn];//计算次数
int Astar(int st, int ed, int k){
Q.push( (Node){ st, 0} );
while( !Q.empty() ){
Node u= Q.top(); Q.pop();
++cnt[u.x];
if(cnt[u.x] == k && u.x == ed) return u.val;//如果出现次数为 k,且为重点的话,返回第 k 短路的值
if(cnt[u.x] > k) continue;
for(int i=head_hx[u.x];i;i=edge_hx[i].u){
int v= edge_hx[i].v, w= edge_hx[i].val;
Q.push((Node){v, u.val + w});//将每个状态加入优先队列
}
}
return -1;
}
int main()
{
n = read(),m=read();
fors(i,1,m){
int u = read(),v = read() , w = read();
add(u,v,w);
add(v,u,w);
}
int st=read(), ed=read(), k=read();
if( st==ed ) ++k;//st == ed 默认存在一条最短的边
Dijkstra(ed);
writen(Astar( st, ed, k ));
return 0;
}
严格 k 短路我们就去掉重复的值(set!!)
每次当到达终点的时候就将值加入 set,判断 set 的 size == k 就可以了,给出完整代码 qwq
set<int> dis_kth;
int Astar(int st, int ed, int k){
Q.push( (Node){ st, 0} );
while( !Q.empty() ){
Node u= Q.top(); Q.pop();
if(u.x == ed) dis_kth.insert(u.val);//如果到达终点就加到 set
if(k == dis_kth.size() && u.x == ed) return u.val;//大小相同并且是终点则直接返回这个值
if(dis_kth.size() > k) continue;
//如果大于 k 的话,就直接 continue
for(int i=head_hx[u.x];i;i=edge_hx[i].u){
int v= edge_hx[i].v, w= edge_hx[i].val;
Q.push((Node){v, u.val + w});
}
}
return -1;
}
数论
乘法逆元
数学 : 一个数 x 的倒数,称乘法逆元,是指一个与 x 相乘的积为 1 的数,记为 $1/x$ 或者 $x ^{-1}$
int exgcd(int a,int b,int &x,int &y){
if(!b){
x=1,y=0;
return a;
}
int k=exgcd(b,a%b,y,x);//注意顺序
y-=a/b*x;
return k;
}
int main(int argc, char const *argv[])
{
n=read(),p=read();
inv[1]=1;
inv[0]=1;//线性递推注意初始化
fors(i,2,n){
inv[i]=(ll)(p - p/i)*inv[p % i] % p;
}
fors(i,1,n){
writen(inv[i]);
}
/*exgcd
fors(i,1,n){
int x,y,a=i;
exgcd(a,p,x,y);
writen((x%p+p)%p);
}
*/
return 0;
}
数论分块
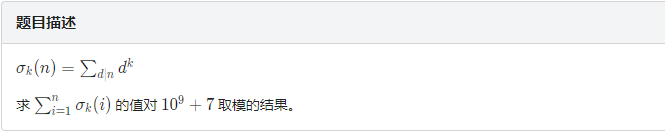
$[n/i]$取值有 $O(sqrt(n))$个
对于每一段连续相等的 $[n/i]$, 直接用该值与对应 $i$的和相乘即可
// 问题转化 这个约数 在 1~n 中出现了多少次,
const int maxn = 1e7+7;
int n,m,k,sum[maxn],tot,prime[maxn],vis[maxn];
const int mod = 1e9+7;
int pows(int a,int b){
int r=1;
while(b){
if(b & 1) r=(r * 1ll * a) % mod;
a = a * 1ll * a % mod; // 注意精度问题
b >>= 1;
}
return r;
}
void init(){
sum[1]=1;//注意初始化
fors(i,2,n){
if(!vis[i]){
prime[++tot] = i;//筛因子
sum[i]=pows(i,k);//计算
}
int maxns=n/i;
for(int j=1;j<=tot && prime[j] >= 1;
}
return ret;
}
const int primes[] = {2,3,5,7,11,13,17,19,23,29};
int isprime(ll n){
fors(i,0,5){
if(primes[i] == n) return 1;
if(primes[i] > n || n % primes[i] == 0) return 0;
ll tmpn = n - 1 , tmps = pows(primes[i] , tmpn , n);
if(tmps != 1) return 0;
while(tmps == 1 && !(tmpn & 1)){
tmpn >>= 1;
tmps = pows(primes[i] , tmpn , n);
if(tmps != 1 && tmps != n-1) return 0;
}
}
return 1;
}
int isprime2(int n){
if(n==1) return 0;
if(n == 2 || n== 3 || n == 5) return 1;
if(n % 6 != 1 && n % 6 != 5) return 0;
int len=sqrt(n);
for(int i=5;i<=len;i+=6){
if(n % i == 0 || n % (i+2) == 0) return 0;
}
return 1;
}
int isprim[maxn],tot,vis[maxn];
void isprime3(int maxns){
vis[1]=1;
fors(i,2,maxns){
if(!vis[i]){
isprim[++tot] = i;
}
for(int j=1;j<=tot && (i * isprim[j] <= maxns); ++j){
vis[i * isprim[j] ] = 1 ;
if(i % isprim[j] == 0) break;
}
}
}
int main() {
ll n=read(),m=read();
isprime3(n);
//while(~scanf("%d,n))/ scanf("") != EOF 对于多组数据的读取
while(m--){
ll k=read();
if(!vis[k]){
puts("Yes");
}
else puts("No");
}
return 0;
}
反素数 :任何小于 $n$ 的正数的约数个数都小于 $n$ 的约数个数
设 $p_i$ 严格递增 并且 $k_i=0$也算在内,则如果则如果 $k_x < k_y$ 并且 $x<y$,那么显然这个数不可能是反素数,因为交换 $k_x$ 和 $k_y$会更好。
所以当 $p_i$ 递增时 k_i$ 是递减的,这个数 $x$才可能是反素数
因为前 $12$个素数的积 $>2*10^9$ 所以最多用到 $12$个素数,手动打表。
const int prime[]={0,2,3,5,7,11,13,17,19,23,29,31,37};
ll sc[20],tc[20],tt[20],n,ansx,ansy;
void dfs(ll x){
tt[x] = 1;
sc[x] = sc[x-1] * prime[x] ;
tc[x] = tc[x-1] << 1;
while(tt[x] <= tt[x-1] && sc[x] <= n){
if(ansx n) return;
if(num == n ){
if(temp < ans)
ans = temp;
return;
}
for(int i = 1;i = ans)break;
if(num = 0 ;--i){
sum = sum * x + w[i];//秦九昭算法,sum 求和从高次项 每次*x + 这一项的系数
}
return sum;
}
const double epxs = 1e-7;
int main(int argc, char const *argv[])
{
n = read();
double l , r ;
cin>>l>>r;
for(int i = n ; i >= 0; --i){
cin>>w[i];//题意是从高次项到低次项 读入,所以这里反向存取
}
while(r - l > epxs){
double mid = (l+r)/2.0;//三分,每次 mid + - 一个 epxs 记住不是 1 是 0.00000001 ~~!!!
if(Check_QJZ(mid - epxs) > Check_QJZ(mid + epxs)){
r = mid;//二分基本操作
}
else l = mid;
}
printf("%0.5lf\n",r);
return 0;
}
Exgcd : $ a * x ≡ ~c ~( ~mod ~b) -> a * x + b * y =c $
- 若 $gcd(a, b) = 1$,则方程 $a*x ≡ c (~mod~ b)$在 $[0, b-1]$上有唯一解。
存在整数 $x$和 y 使 $ax_1 + by_1 = gcd(a, b) = 1$,即我们可以求出 $a x ≡ 1 (~mod~b)$的解 $x0$。加上或减去若干倍 $b$都是该方程的解.
- 若 gcd(a, b) = d,则方程 ax ≡ c (mod b) 在 [0, b/d – 1] 上有唯一解。
如果得到 $ax ≡ c (~mod ~b)$的某一特解 $X$,那么令 $g = b/gcd(a, b)$,可知 $x$在 $[0, g-1]$上有唯一解,所以 $x = (X ~mod~ g + g) ~mod~ g$就可以求出最小非负整数解 $x$ , $X mod ~ g$可能是负值就加上 $g$, 再模一下 $g$就在 $[0, g-1] $内了。
int Exgcd(int a, int b , int &x , int &y){
if(!b){
x = 1;
y = 0;
return a;
}
int tmp = Exgcd(b , a%b , y ,x);
y -= a/b*x;
return tmp;
}
x = (x + b/gcd(a,b)) % (b/gcd(a,b));
ExCRT 用于求解同余方程组
- $~~~~~~~~~~~~~~~~~~~~~~~~~~~~x ≡ b_1 (~mod ~a_1 )$
-
$~~~~~~~~~~~~~~~~~~~~~~~~~~~~x ≡ b_2 (~mod ~a_2 )$
-
$~~~~~~~~~~~~~~~~~~~~~~~~~~~~x ≡ b_3 (~mod ~a_3 )$
int a[maxn] , b[maxn] , n , m , ans ;
int Exgcd(int a, int b , int &x , int &y){
if(!b){
x = 1;
y = 0;
return a;
}
int tmp = Exgcd(b , a%b , y ,x);
y -= a/b*x;
return tmp;
}
int mul(int a,int b,int mod){
a %= mod , b %= mod;
return ((a * b - (LL)(((long double) a * b + 0.5)/mod ) * mod) + mod) % mod;
}
int Excrt(){
int ans = b[1] , fir = a[1] , x = 0, y=0;
fors(i,2,n){
int lastx = fir;//先保存上一个的值 , 只用来 求 exgcd
int st = a[i];
int bs = (b[i] - ans % st + st) % st;// 被模数的差值
int tmp = Exgcd(lastx , st , x , y);//a[i-1] , a[i] , 求解
if(bs % tmp != -1) return -1;// 如果差值不能 整除 gcd return -1;
int lcms = st/tmp;
x = mul(x , bs/tmp , lcms);// *(b2 - b1)为最小非负数解
ans += fir * x;
fir *= lcms; //对上一个 a[] 乘以 lcm
ans = (ans + fir) % fir;//每次 mod 上一次 fir 求最小非负数解
}
return ans;
}
signed main()
{
n = read();
fors(i,1,n) a[i] = read() , b[i] = read();
cout<<Excrt()<<endl;
return 0;
}
BSGS
已知数 $a,p,b$,求满足 $a^x≡b~( ~mod~ p)$的最小自然数 $x$ 。当 $p$质数时
$(a^i)^m≡a^j$ $×b~mod~p$ ——$m=$⌈$sqrt(p)$⌉
LL BSGS(LL a , LL b , LL p){
int block = sqrt(p) + 0.5;//类似分块 不过要 ceil
int base = 1;//初始 base = 1, 先模拟 存 b * a^j
map<LL , LL> maps;
int tmp = 0;//保留上一个的值 ,计算 a ^ block
fors(i,0,block){//从 幂 0 开始
maps[mul(base , b , p)] = i+1;//保留 i+1 当求解的时候,要-1
tmp = base;
base = mul(base , a , p);//每次直接乘以 a, 免去快速幂
}
base = tmp;//保留上一个的值
fors(i,1,block){//开始查询 从 幂 1 开始
if(maps[base]){//他、如果存在这个值则直接返回 ,要记得 i 乘以 block
return i * block - (maps[base] - 1);
}
base = mul(base , tmp , p);//每次计算 (a^m) ^i
}
return -1;//无解则返回 -1;
}
ExBSGS
处理 p 不为质数的情况 , 主要是使用 gcd 对式子同除以 gcd 使 p 为质数 qwq
注意保留其中的答案
int ExBSGS(int a,int b,int p){
a %= p , b %= p ;
if(b == 1) return 0;
//特判 , 如果 b == 1 那么 a ^ 0 = 1
int t = 1 , cnt = 0;
while(1){
int g = gcd(a,p);
if(g == 1) break;//如果 a, p 没有最大公约数,表示已经是质数了
if(b % g != 0) return -1;//是 b % gcd !!! b 不整除 gcd 则无解
p /= g , b /= g , t = mul(t , a / g , p);
++cnt;// 表示已经
if(b == t) return cnt;
}
Maps maps;
maps.clear();
int block = sqrt(p)+0.5;
int nows = t ;
int base = 1;
int tmp = 1;
fors(i,0,block){//从 幂 0 开始
maps.insert(mul(base , b , p) , i);
tmp = base;
base = mul(base , a , p);
}
base = tmp;
fors(i,1,block){
nows = mul(nows, base , p);//注意要使用 gcd 中的保存的幂 作为底,每次 *a^m
if(maps.query(nows) != -1){
return i * block - maps.query(nows) + cnt;//记得加上 gcd 中的次数
}
}
return -1;
}
杨辉三角形
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
- 由 1 开始,正整数在杨辉三角形出现的次数为:∞,1, 2, 2, 2, 3, 2, 2, 2, 4, 2, 2, 2, 2, 4…
-
杨辉三角每一行的平方和在杨辉三角出现奇数次
-
杨辉三角每一行的和是 2 的幂。
-
第 n 行的数字个数为 n 个。
-
第 $ {\displaystyle n} $ 行的第 $ {\displaystyle k} $个数字为组合数 $ {\displaystyle C_{n-1}^{k-1}} $。
-
第 ${\displaystyle n}$ 行数字和为 ${\displaystyle 2^{n-1}}$。
-
除每行最左侧与最右侧的数字以外,每个数字等于它的左上方与右上方两个数字之和(也就是说,第 ${\displaystyle n} $行第 ${\displaystyle k}$ 个数字等于第 ${\displaystyle n-1} $行的第 $ {\displaystyle k-1}$ 个数字与第 $k$ 个数字的和)。这是因为有组合恒等式:$ {\displaystyle C_{n+1}^{i+1}=C_{n}^{i}+C_{n}^{i+1}} $。可用此性质写出整个杨辉三角形
int C[201][201];
C[0][0] = 1;//要 C[0][0] 初始化为 1
fors(i,1,20){//行
C[i][0] = 1;//记住每一行第一个元素为 1
fors(j,1,i)//列
C[i][j] = c[i-1][j] + c[i-1][j-1];
}
Lucas 组合数
$Lucas(n,m,p) = C(n ~mod~ p, m ~mod~ p) * Lucas(n/p , m/p ,p)$
$Lucas(n,0,p) = 1 , C(n,m) = (n! / (n-m)!)^{p-2} mod p $
int a[maxn];
LL C(LL n ,LL m){
if(m > n) return 0;//注意 先求 m! 的逆元 在(n-m)!的逆元 接着 和 n!全部乘起来
return ((a[n] * pows(a[m] , p-2 , p)) % p * pows(a[n-m] , p-2 , p) % p); //注意是组合,不是排列 ,所以要 * m!的倒数(逆元)
}
LL lucas(LL n , LL m){
if(!m) return 1;
return C(n % p ,m % p) * lucas(n / p , m / p) % p;
}//O(p) 的处理 -》C 所以是 % 接着 lucas -》/p
int main(){
int t = read();
while(t--){
int n = read() , m = read() ;
p = read();
a[0] = 1;//注意初始化为 1 求 1~P 的阶层
fors(i,1,p)
a[i] = (a[i-1] * i) % p;
writen(lucas(n+m,m));
}
return 0;
}
卡特兰数
只要看到能转变为合法括号序列问题的或者出栈序列问题的求方案数的题就上卡特兰数就行了
$h(n)=C(2n,n)-C(2n,n-1) (n = 0,1,2,…)$
n = read();
C[0][0] = 1;
fors(i,1,n*2){
C[i][0] = 1;
fors(j,1,i)
C[i][j] = C[i-1][j] + C[i-1][j-1];
}
writen([2*n][n] - C[n*2][n-1]);
矩阵
矩阵乘法 分别给定 $n×p$ 和 $p×m$ 的两个矩阵 $A$和 $B$,求 $A×B$。
// a.m[i][k]*b.m[k][j] -> 类似 floyd i-k-j - c[i][j]
struct node
{
int m[507][507];
}a,b,c;
int n,m,p;
const int mod=1e9+7;
int main(int argc, char const *argv[])
{
n=read(),p=read(),m=read();
fors(i,1,n)
fors(j,1,p)
a.m[i][j]=read();
fors(i,1,p)
fors(j,1,m)
b.m[i][j]=read();
mem(c.m,0);
fors(i,1,n)
fors(k,1,p)
fors(j,1,m)
c.m[i][j]=(c.m[i][j] + a.m[i][k]*b.m[k][j]%mod + mod) % mod;;
fors(i,1,n){
fors(j,1,m)
write(c.m[i][j]),putchar(32);
putchar(10);
}
return 0;
}

node mul(node a,node b){
node ans;
//mem(ans.m,0);
fors(i,1,3)//矩阵乘法 注意 Floyd , LL 精度需要
fors(k,1,3){
int tmp = a.m[i][k];
fors(j,1,3)
ans.m[i][j] = (ans.m[i][j] + tmp * b.m[k][j] ) % mod;
}
return ans;
}
int pows(int k){
node ans,e;
//mem(ans.m,0);
//mem(e.m,0);
fors(i,1,3) e.m[i][i] = 1; //单位矩阵对角为 1
//注意是先单位矩阵 * 目标矩阵
ans.m[1][1] = ans.m[1][3] = ans.m[2][1] = ans.m[3][2] = 1;
//初始化矩阵
--k;// 注意 是 k-1 次方
while(k){
if(k & 1) e = mul(e , ans);
ans = mul(ans , ans);
k >>= 1;
}
return e.m[1][1];// 注意求出来的在第一个位置
}
广义的斐波那契数列是指形如 $a_n=p * a_{n-1}+q* a_{n-2}$的数列。今给定数列的两系数 $p$和 $q$,以及数列的最前两项 $a_1$
和 $a_2$ ,另给出两个整数 $n$和 $m$,试求数列的第 $n$项 $a_n$ 除以 $m$的余数。

int pows(int a1,int a2,int p,int q,int k){
node ans,e;
e.m[1][1] = a2,e.m[1][2] = a1;//初始第一项,第二项
ans.m[1][1] = p , ans.m[1][2] = 1,ans.m[2][1] = q;//要乘的矩阵
while(k){
if(k & 1) e = mul(e , ans);//每次对初始矩阵 *
ans = mul(ans , ans);
k >>= 1;
}
return e.m[1][1];
}
signed main(){
int p = read() , q = read() , a1 = read() , a2 = read() , n = read();
mod = read();
if(n == 1) writen(a1);
else if(n == 2) writen(a2);
else writen(pows(a1,a2,p,q,n-2));//自己认为因为已经给出两项的值所以这里的幂要-2
return 0;
}
然后给弱弱的自己背下来一些板子
1.$f(n)=af(n-1)+bf(n-2)+c$;(a,b,c 是常数)
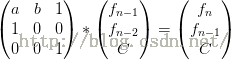
2.$f(n)=c^n-f(n-1) $;(c 是常数)
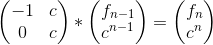
3. 斐波拉契数列的第 n 项和第 m 项的最大公约数是 $gcd(F[n],F[m])=F[gcd(n,m)]$
(反正我证不来)
高斯消元法
给定一个线性方程组,对其求解
想象一个矩阵(最终好像就是一左下半角矩阵(应该是左对角下面一半都为 0))
void Cal_s(){
fors(i,1,n){
int maxn_i = i;//找这一列系数最大值
fors(j,i+1,n){
if(fabs(maps[maxn_i][i]) < fabs(maps[j][i])){
maxn_i = j;
}
}//如果系数最大的为 0 则无解
if(fabs(maps[maxn_i][i]) =1 ; --i){///从 n-1 开始 , 每次去方程的答案作为起始值
ans[i] = maps[i][n+1];
fors(j,i+1,n)//每次- 从上一个方程的 ans[j~n] * maps 第 i 行第 j 的值
ans[i] -= (maps[i][j] * ans[j]);
}
}
欧拉函数
$phi(x)$表示小于等于 x 的正整数中有几个与其互质 (出现的 p,q 都是质数)
- $phi(a~*~b) = phi(a) * phi(b)$ (a,b 互质)
-
$phi(p)=p-1$
-
$phi(i * p)=p * phi(i)~ (i~mod~p==0)$
-
$phi(i * p) = phi(i) * (p-1) (i ~mod ~p!=0)$
int phi[p];
void Phi(int maxn) {
phi[1] = 1;
for(int i=2; i<=maxn; ++i)
if(!phi[i]) {
for(int j=i; j<=maxn; j+=i) {
if(!phi[j]) phi[j] = j;
phi[j] = phi[j] / i * (i-1);
}
}
}
//顺便筛素数的版本 (耗空间), 但快,推荐离线查找 maxn 最大值(防止 MLE)
void Phi(int maxn){
phi[1]=1;
int tot=0;
fors(i,2,maxn){
if(!vis[i]){
prime[++tot]=i;
phi[i]=i-1;//对应第二定理
}
for(int j=1,k;j<=tot && (k=i*prime[j])<=maxn;++j){
vis[k]=1;//素数的判定
if(i % prime[j]==0) {
phi[k]=phi[i]*prime[j];//对应第三定理
break;
}
phi[k]=phi[i]*(prime[j]-1);//对应第四定理
}
}
}
/*int OL(int n) {//单点查询 Phi 不过可能比较慢
int x=sqrt(n+0.5),ans=n;
fors(i,2,x)
if(n%i==0) {
ans=ans/i*(i-1);
while(n%i==0) n/=i;//分解质因数 第一定理
}
if(n>1) ans=ans/n*(n-1);
return ans;
//P2158 是个简单的求 Phi *2+1 就 ok 了,不过你要手动模拟一下才知道为什么。
}
*/
欧拉降幂

求 $a^b~mod~c~$可以转化为 $a^{~b~mod~phi(~c~)+phi(~c~)}~mod~c$
注意当 $phi(c)==1 $时返回 $0$;
int solve(int mods){
if(mods==1) return 0;
int ok=phi(mods);
return pows(2,solve(ok)+ok,mods);//这里只是求无限的 2^2^2^2...%p
}
一些定理 :
设 $ p$ 是质数
- 威尔逊定理:$(p – 1) ! ≡ -1 ( ~mod ~p )$
威尔逊定理的逆定理也是成立的
若 $p = a * b$
有 $(p – 1)! ≡ 0 ( ~mod ~a )$
⇒ $(p – 1)! ≡ 0 ( ~mod~ p )$
- Euler 定理 == 欧拉
若 n 与 a 互质,则 $a^{φ(n)} ≡ 1 ~mod~ n$
- 欧拉函数
$1~1~2~2~4~2~6~4~6~4~10~4~12~6~8~8~16~6~18~8~$ –> Phi(i)
- 阶层
$1~2~6~24~120~720~5040~40320~362880~3628800~39916800….$ $~~~n!$
后面爆了
- 卡特兰数
$1~ 1~ 2~ 5~ 14~ 42~ 132~ 429~ 1430~ 4862~ 16796~ 58786~ 208012~ 742900~ $
- 组合数
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
最后祝大家 NOIP 2018 能有个好成绩 QvQ

5 条评论
yzhx · 2019年11月13日 4:33 下午
菜,这些东西都是我去年 ak 联赛剩下的,简单得很,这些东西我随便切,洛谷搜索 YZHX,我贼强
Remmina · 2019年11月13日 11:36 下午
咦,是长郡小朋友被机惨了吗 233333
十分熟悉的 IP QwQ
YZHX · 2019年11月14日 7:58 上午
是的。。。对不起
B_Z_B_Y · 2018年11月2日 12:10 上午
qwq, 我一不小心更新了图片,代码
>> <<又被转义了,看了是 rp 又降了 qwq【题解】 [SDOI2011]计算器 数论 BSGS LUOGU 2485 – B_Z_B_Y – K-XZY · 2018年11月6日 9:58 下午
[…] 自己的经验和模板 $~~~~~~$(打个广告)[…]